This is the multi-page printable view of this section. Click here to print.
Amministrazione del Cluster
- 1: Panoramica sull'amministrazione del cluster
- 2: Certificati
- 3: Cloud Providers
- 4: Gestione delle risorse
- 5: Cluster Networking
- 6: Log di registrazione
- 7: Configurazione della raccolta dati kubelet
- 8: Proxy in Kubernetes
- 9: Metriche del responsabile del controller
- 10: Installazione dei componenti aggiuntivi
1 - Panoramica sull'amministrazione del cluster
La panoramica dell'amministrazione del cluster è per chiunque crei o gestisca un cluster Kubernetes. Presuppone una certa dimestichezza con i core Kubernetes concetti.
Progettare un cluster
Consulta le guide di Setup per avere degli esempi su come pianificare, impostare e configurare cluster Kubernetes. Le soluzioni elencate in questo articolo sono chiamate distribuzioni.
Prima di scegliere una guida, ecco alcune considerazioni:
- Vuoi provare Kubernetes sul tuo computer o vuoi creare un cluster multi-nodo ad alta disponibilità? Scegli la distro che più si adatti alle tue esigenze.
- Se si sta progettando per l'alta disponibilità, impara a configurare cluster in più zone.
- Utilizzerai un cluster di Kubernetes ospitato, come Motore di Google Kubernetes o che ospita il tuo cluster?
- Il tuo cluster sarà on-premises o nel cloud (IaaS)? Kubernetes non supporta direttamente i cluster ibridi. Invece, puoi impostare più cluster.
- Se stai configurando Kubernetes on-premises, considera quale modello di rete si adatti meglio.
- Eseguirai Kubernetes su hardware "bare metal" o su macchine virtuali (VM)?
- Vuoi solo eseguire un cluster, oppure ti aspetti di fare lo sviluppo attivo del codice del progetto di Kubernetes? In quest'ultimo caso, scegli una distribuzione sviluppata attivamente. Alcune distribuzioni utilizzano solo versioni binarie, ma offrono una maggiore varietà di scelte
- Familiarizzare con i componenti necessari per eseguire un cluster.
Nota: non tutte le distro vengono mantenute attivamente. Scegli le distro che sono state testate con una versione recente di Kubernetes.
Managing a cluster
-
Gestione di un cluster descrive diversi argomenti relativi al ciclo di vita di un cluster: creazione di un nuovo cluster, aggiornamento dei nodi master e worker del cluster, esecuzione della manutenzione del nodo (ad esempio kernel aggiornamenti) e aggiornamento della versione dell'API di Kubernetes di un cluster in esecuzione.
-
Scopri come gestire i nodi.
-
Scopri come impostare e gestire la quota di risorse per i cluster condivisi.
Proteggere un cluster
-
Certificati descrive i passaggi per generare certificati utilizzando diverse catene di strumenti.
-
Kubernetes Container Environment descrive l'ambiente per i contenitori gestiti Kubelet su un nodo Kubernetes.
-
Controllo dell'accesso all'API di Kubernetes descrive come impostare le autorizzazioni per gli utenti e gli account di servizio.
-
Autenticazione spiega l'autenticazione in Kubernetes, incluse le varie opzioni di autenticazione.
-
Autorizzazione è separato dall'autenticazione e controlla come vengono gestite le chiamate HTTP.
-
Utilizzo dei controller di ammissione spiega i plug-in che intercettano le richieste al server API Kubernetes dopo l'autenticazione e l'autorizzazione.
-
Uso di Sysctls in un cluster Kubernetes descrive a un amministratore come utilizzare lo strumento da riga di comando
sysctlper impostare i parametri del kernel. -
Controllo descrive come interagire con i log di controllo di Kubernetes.
Securing the kubelet
Optional Cluster Services
-
Integrazione DNS descrive come risolvere un nome DNS direttamente su un servizio Kubernetes.
-
Registrazione e monitoraggio delle attività del cluster spiega come funziona il logging in Kubernetes e come implementarlo.
2 - Certificati
Quando si utilizza l'autenticazione del certificato client, è possibile generare certificati
manualmente tramite easyrsa, openssl o cfssl.
easyrsa
** easyrsa ** può generare manualmente certificati per il tuo cluster.
- Scaricare, decomprimere e inizializzare la versione patched di easyrsa3.
curl -LO https://dl.k8s.io/easy-rsa/easy-rsa.tar.gz tar xzf easy-rsa.tar.gz cd easy-rsa-master / easyrsa3 ./easyrsa init-pki
- Generare una CA. (
--batchimposta la modalità automatica.--req-cndefault CN da usare.)
./easyrsa --batch "--req-cn = $ {MASTER_IP} @ date +% s "build-ca nopass
- Genera certificato e chiave del server.
L'argomento
--subject-alt-nameimposta i possibili IP e nomi DNS del server API accessibile con. IlMASTER_CLUSTER_IPè solitamente il primo IP dal servizio CIDR che è specificato come argomento--service-cluster-ip-rangeper il server API e il componente del controller controller. L'argomento--daysè usato per impostare il numero di giorni dopodiché scade il certificato. L'esempio sotto riportato assume anche che tu stia usandocluster.localcome predefinito Nome di dominio DNS
./easyrsa --subject-alt-name = "IP: $ {MASTER_IP},"
"IP: $ {} MASTER_CLUSTER_IP,"
"DNS: kubernetes,"
"DNS: kubernetes.default,"
"DNS: kubernetes.default.svc,"
"DNS: kubernetes.default.svc.cluster,"
"DNS: kubernetes.default.svc.cluster.local"
--days = 10000
build-server-full server nopass
- Copia
pki / ca.crt,pki / issued / server.crtepki / private / server.keynella tua directory. - Compilare e aggiungere i seguenti parametri nei parametri di avvio del server API:
--client-ca-file =/YourDirectory/ca.crt --tls-cert-file =/YourDirectory/server.crt --tls-chiave file privato=/YourDirectory/server.key
openssl
** openssl ** può generare manualmente certificati per il tuo cluster.
- Genera un tasto approssimativo con 2048 bit:
openssl genrsa -out ca.key 2048
- In base al tasto approssimativo, generare ca.crt (utilizzare -giorni per impostare il tempo effettivo del certificato):
openssl req -x509 -new -nodes -key ca.key -subj "/ CN = $ {MASTER_IP}" -days 10000 -out ca.crt
- Genera un server.key con 2048 bit:
openssl genrsa -out server.key 2048
-
Creare un file di configurazione per generare una richiesta di firma del certificato (CSR). Assicurati di sostituire i valori contrassegnati da parentesi angolari (ad esempio
<MASTER_IP>) con valori reali prima di salvarlo in un file (ad esempiocsr.conf). Si noti che il valore diMASTER_CLUSTER_IPè l'IP del cluster di servizio per il Server API come descritto nella sottosezione precedente. L'esempio sotto riportato assume anche che tu stia usandocluster.localcome predefinito Nome di dominio DNS[ req ] default_bits = 2048 prompt = no default_md = sha256 req_extensions = req_ext distinguished_name = dn [ dn ] C = <country> ST = <state> L = <city> O = <organization> OU = <organization unit> CN = <MASTER_IP> [ req_ext ] subjectAltName = @alt_names [ alt_names ] DNS.1 = kubernetes DNS.2 = kubernetes.default DNS.3 = kubernetes.default.svc DNS.4 = kubernetes.default.svc.cluster DNS.5 = kubernetes.default.svc.cluster.local IP.1 = <MASTER_IP> IP.2 = <MASTER_CLUSTER_IP> [ v3_ext ] authorityKeyIdentifier=keyid,issuer:always basicConstraints=CA:FALSE keyUsage=keyEncipherment,dataEncipherment extendedKeyUsage=serverAuth,clientAuth subjectAltName=@alt_names -
Generate the certificate signing request based on the config file:
openssl req -new -key server.key -out server.csr -config csr.conf -
Generare il certificato del server usando ca.key, ca.crt e server.csr:
openssl x509 -req -in server.csr -CA ca.crt -CAkey ca.key \ -CAcreateserial -out server.crt -days 10000 \ -extensions v3_ext -extfile csr.conf -sha256 -
Visualizza il certificato:
openssl x509 -noout -text -in ./server.crt
Infine, aggiungi gli stessi parametri nei parametri di avvio del server API.
cfssl
** cfssl ** è un altro strumento per la generazione di certificati.
-
Scaricare, decomprimere e preparare gli strumenti da riga di comando come mostrato di seguito. Si noti che potrebbe essere necessario adattare i comandi di esempio in base all'hardware architettura e versione di cfssl che stai utilizzando.
curl -L https://pkg.cfssl.org/R1.2/cfssl_linux-amd64 -o cfssl chmod +x cfssl curl -L https://pkg.cfssl.org/R1.2/cfssljson_linux-amd64 -o cfssljson chmod +x cfssljson curl -L https://pkg.cfssl.org/R1.2/cfssl-certinfo_linux-amd64 -o cfssl-certinfo chmod +x cfssl-certinfo -
Create a directory to hold the artifacts and initialize cfssl:
mkdir cert cd cert ../cfssl print-defaults config > config.json ../cfssl print-defaults csr > csr.json -
Creare un file di configurazione JSON per generare il file CA, ad esempio,
ca-config.json:{ "signing": { "default": { "expiry": "8760h" }, "profiles": { "kubernetes": { "usages": [ "signing", "key encipherment", "server auth", "client auth" ], "expiry": "8760h" } } } } -
Creare un file di configurazione JSON per la richiesta di firma del certificato CA (CSR), ad esempio,
Ca-csr.json. Assicurarsi di sostituire i valori contrassegnati da parentesi angolari con valori reali che si desidera utilizzare.{ "CN": "kubernetes", "key": { "algo": "rsa", "size": 2048 }, "names":[{ "C": "<country>", "ST": "<state>", "L": "<city>", "O": "<organization>", "OU": "<organization unit>" }] } -
Generate CA key (
ca-key.pem) and certificate (ca.pem):../cfssl gencert -initca ca-csr.json | ../cfssljson -bare ca -
Creare un file di configurazione JSON per generare chiavi e certificati per l'API server, ad esempio,
server-csr.json. Assicurati di sostituire i valori tra parentesi angolari con valori reali che si desidera utilizzare.MASTER_CLUSTER_IPè il cluster di servizio IP per il server API come descritto nella sottosezione precedente. L'esempio sotto riportato assume anche che tu stia usandocluster.localcome predefinito Nome di dominio DNS{ "CN": "kubernetes", "hosts": [ "127.0.0.1", "<MASTER_IP>", "<MASTER_CLUSTER_IP>", "kubernetes", "kubernetes.default", "kubernetes.default.svc", "kubernetes.default.svc.cluster", "kubernetes.default.svc.cluster.local" ], "key": { "algo": "rsa", "size": 2048 }, "names": [{ "C": "<country>", "ST": "<state>", "L": "<city>", "O": "<organization>", "OU": "<organization unit>" }] } -
Generare la chiave e il certificato per il server API, che sono per impostazione predefinita salvati nel file
server-key.pemeserver.pemrispettivamente:../cfssl gencert -ca=ca.pem -ca-key=ca-key.pem \ --config=ca-config.json -profile=kubernetes \ server-csr.json | ../cfssljson -bare server
Distributing Self-Signed CA Certificate
Un nodo client può rifiutarsi di riconoscere un certificato CA autofirmato come valido. Per una distribuzione non di produzione o per una distribuzione che viene eseguita dietro una società firewall, è possibile distribuire un certificato CA autofirmato a tutti i client e aggiornare l'elenco locale per i certificati validi.
Su ciascun client, eseguire le seguenti operazioni:
$ sudo cp ca.crt /usr/local/share/ca-certificates/kubernetes.crt
$ sudo update-ca-certificates
Updating certificates in /etc/ssl/certs...
1 added, 0 removed; done.
Running hooks in /etc/ca-certificates/update.d....
done.
Certificates API
È possibile utilizzare l'API certificates.k8s.io per eseguire il provisioning
certificati x509 da utilizzare per l'autenticazione come documentato
here.
3 - Cloud Providers
Questa pagina spiega come gestire Kubernetes in esecuzione su uno specifico fornitore di servizi cloud.
kubeadm
kubeadm è un'opzione popolare per la creazione di cluster di kuberneti. kubeadm ha opzioni di configurazione per specificare le informazioni di configurazione per i provider cloud. Ad esempio un tipico il provider cloud in-tree può essere configurato utilizzando kubeadm come mostrato di seguito:
apiVersion: kubeadm.k8s.io/v1beta1
kind: InitConfiguration
nodeRegistration:
kubeletExtraArgs:
cloud-provider: "openstack"
cloud-config: "/etc/kubernetes/cloud.conf"
---
apiVersion: kubeadm.k8s.io/v1beta1
kind: ClusterConfiguration
kubernetesVersion: v1.13.0
apiServer:
extraArgs:
cloud-provider: "openstack"
cloud-config: "/etc/kubernetes/cloud.conf"
extraVolumes:
- name: cloud
hostPath: "/etc/kubernetes/cloud.conf"
mountPath: "/etc/kubernetes/cloud.conf"
controllerManager:
extraArgs:
cloud-provider: "openstack"
cloud-config: "/etc/kubernetes/cloud.conf"
extraVolumes:
- name: cloud
hostPath: "/etc/kubernetes/cloud.conf"
mountPath: "/etc/kubernetes/cloud.conf"
I provider cloud in-tree in genere richiedono sia --cloud-provider e --cloud-config specificati nelle righe di
comando per kube-apiserver, kube-controller-manager
e il Kubelet. Anche il contenuto del file specificato in --cloud-config per ciascun provider
è documentato di seguito.
Per tutti i fornitori di servizi cloud esterni, seguire le istruzioni sui singoli repository.
AWS
Questa sezione descrive tutte le possibili configurazioni che possono essere utilizzato durante l'esecuzione di Kubernetes su Amazon Web Services.
Node Name
Il provider cloud AWS utilizza il nome DNS privato dell'istanza AWS come nome dell'oggetto Nodo Kubernetes.
Load Balancers
È possibile impostare bilanciamento del carico esterno per utilizzare funzionalità specifiche in AWS configurando le annotazioni come mostrato di seguito.
apiVersion: v1
kind: Service
metadata:
name: example
namespace: kube-system
labels:
run: example
annotations:
service.beta.kubernetes.io/aws-load-balancer-ssl-cert: arn:aws:acm:xx-xxxx-x:xxxxxxxxx:xxxxxxx/xxxxx-xxxx-xxxx-xxxx-xxxxxxxxx #replace this value
service.beta.kubernetes.io/aws-load-balancer-backend-protocol: http
spec:
type: LoadBalancer
ports:
- port: 443
targetPort: 5556
protocol: TCP
selector:
app: example
È possibile applicare impostazioni diverse a un servizio di bilanciamento del carico in AWS utilizzando annotations. Quanto segue descrive le annotazioni supportate su ELB AWS:
service.beta.kubernetes.io / aws-load-balancer-access-log-emit-interval: utilizzato per specificare l'intervallo di emissione del registro di accesso.service.beta.kubernetes.io / aws-load-balancer-access-log-enabled: utilizzato sul servizio per abilitare o disabilitare i log di accesso.service.beta.kubernetes.io / aws-load-balancer-access-log-s3-bucket-name: usato per specificare il nome del bucket di log degli accessi s3.service.beta.kubernetes.io / aws-load-balancer-access-log-s3-bucket-prefix: utilizzato per specificare il prefisso del bucket del registro di accesso s3.service.beta.kubernetes.io / aws-load-balancer-additional-resource-tags: utilizzato sul servizio per specificare un elenco separato da virgole di coppie chiave-valore che verranno registrate come tag aggiuntivi nel ELB. Ad esempio:"Key1 = Val1, Key2 = Val2, KeyNoVal1 =, KeyNoVal2".service.beta.kubernetes.io / aws-load-balancer-backend-protocol: utilizzato sul servizio per specificare il protocollo parlato dal backend (pod) dietro un listener. Sehttp(predefinito) ohttps, viene creato un listener HTTPS che termina la connessione e analizza le intestazioni. Se impostato susslotcp, viene utilizzato un listener SSL "raw". Se impostato suhttpeaws-load-balancer-ssl-certnon viene utilizzato, viene utilizzato un listener HTTP.service.beta.kubernetes.io / aws-load-balancer-ssl-cert: utilizzato nel servizio per richiedere un listener sicuro. Il valore è un certificato ARN valido. Per ulteriori informazioni, vedere ELB Listener Config CertARN è un ARN certificato IAM o CM, ad es.ARN: AWS: ACM: US-est-1: 123456789012: certificato / 12345678-1234-1234-1234-123456789012.service.beta.kubernetes.io / aws-load-balancer-connection-draining-enabled: utilizzato sul servizio per abilitare o disabilitare il drenaggio della connessione.service.beta.kubernetes.io / aws-load-balancer-connection-draining-timeout: utilizzato sul servizio per specificare un timeout di drenaggio della connessione.service.beta.kubernetes.io / aws-load-balancer-connection-idle-timeout: utilizzato sul servizio per specificare il timeout della connessione inattiva.service.beta.kubernetes.io / aws-load-balancer-cross-zone-load-bilanciamento-abilitato: utilizzato sul servizio per abilitare o disabilitare il bilanciamento del carico tra zone.service.beta.kubernetes.io / aws-load-balancer-extra-security-groups: utilizzato sul servizio per specificare gruppi di sicurezza aggiuntivi da aggiungere a ELB creatoservice.beta.kubernetes.io / aws-load-balancer-internal: usato nel servizio per indicare che vogliamo un ELB interno.service.beta.kubernetes.io / aws-load-balancer-proxy-protocol: utilizzato sul servizio per abilitare il protocollo proxy su un ELB. Al momento accettiamo solo il valore*che significa abilitare il protocollo proxy su tutti i backend ELB. In futuro potremmo regolarlo per consentire l'impostazione del protocollo proxy solo su determinati backend.service.beta.kubernetes.io / aws-load-balancer-ssl-ports: utilizzato sul servizio per specificare un elenco di porte separate da virgole che utilizzeranno listener SSL / HTTPS. Il valore predefinito è*(tutto)
Le informazioni per le annotazioni per AWS sono tratte dai commenti su aws.go
Azure
Node Name
Il provider cloud di Azure utilizza il nome host del nodo (come determinato dal kubelet o sovrascritto
con --hostname-override) come nome dell'oggetto Nodo Kubernetes. Si noti che il nome del nodo Kubernetes deve
corrispondere al nome VM di Azure.
CloudStack
Node Name
Il provider cloud CloudStack utilizza il nome host del nodo (come determinato dal kubelet o sovrascritto
con --hostname-override) come nome dell'oggetto Nodo Kubernetes. Si noti che il nome del nodo Kubernetes deve
corrispondere al nome VM di CloudStack.
GCE
Node Name
Il provider cloud GCE utilizza il nome host del nodo (come determinato dal kubelet o sovrascritto
con --hostname-override) come nome dell'oggetto Nodo Kubernetes. Si noti che il primo segmento del nome del nodo
Kubernetes deve corrispondere al nome dell'istanza GCE (ad esempio, un nodo denominato kubernetes-node-2.c.my-proj.internal
deve corrispondere a un'istanza denominata kubernetes-node-2) .
OpenStack
Questa sezione descrive tutte le possibili configurazioni che possono essere utilizzato quando si utilizza OpenStack con Kubernetes.
Node Name
Il provider cloud OpenStack utilizza il nome dell'istanza (come determinato dai metadati OpenStack) come nome dell'oggetto Nodo Kubernetes. Si noti che il nome dell'istanza deve essere un nome nodo Kubernetes valido affinché kubelet registri correttamente il suo oggetto Node.
Services
Il provider cloud OpenStack implementazione per Kubernetes supporta l'uso di questi servizi OpenStack da la nuvola sottostante, ove disponibile:
| Servizio | Versioni API | Richiesto | | -------------------------- | ---------------- | ----- ----- | | Block Storage (Cinder) | V1 †, V2, V3 | No | | Calcola (Nova) | V2 | No | | Identity (Keystone) | V2 ‡, V3 | Sì | | Load Balancing (Neutron) | V1§, V2 | No | | Load Balancing (Octavia) | V2 | No |
† Il supporto dell'API di storage block V1 è obsoleto, il supporto dell'API di Storage Block V3 era aggiunto in Kubernetes 1.9.
‡ Il supporto dell'API di Identity V2 è obsoleto e verrà rimosso dal provider in una versione futura. A partire dalla versione "Queens", OpenStack non esporrà più il file Identity V2 API.
§ Il supporto per il bilanciamento del carico V1 API è stato rimosso in Kubernetes 1.9.
La scoperta del servizio si ottiene elencando il catalogo dei servizi gestito da
OpenStack Identity (Keystone) usando auth-url fornito nel provider
configurazione. Il fornitore si degraderà garbatamente in funzionalità quando
I servizi OpenStack diversi da Keystone non sono disponibili e semplicemente disconoscono
supporto per le caratteristiche interessate. Alcune funzionalità sono anche abilitate o disabilitate
in base all'elenco delle estensioni pubblicate da Neutron nel cloud sottostante.
cloud.conf
Kubernetes sa come interagire con OpenStack tramite il file cloud.conf. È il file che fornirà a Kubernetes le credenziali e il percorso per l'endpoint auth di OpenStack. È possibile creare un file cloud.conf specificando i seguenti dettagli in esso
Typical configuration
Questo è un esempio di una configurazione tipica che tocca i valori più spesso devono essere impostati. Punta il fornitore al Keystone del cloud di OpenStack endpoint, fornisce dettagli su come autenticarsi con esso e configura il bilanciamento del carico:
[Global]
username=user
password=pass
auth-url=https://<keystone_ip>/identity/v3
tenant-id=c869168a828847f39f7f06edd7305637
domain-id=2a73b8f597c04551a0fdc8e95544be8a
[LoadBalancer]
subnet-id=6937f8fa-858d-4bc9-a3a5-18d2c957166a
Global
Queste opzioni di configurazione per il provider OpenStack riguardano la sua globalità
configurazione e dovrebbe apparire nella sezione [Globale] di cloud.conf
file:
auth-url(obbligatorio): l'URL dell'API keystone utilizzata per l'autenticazione. Sopra Pannelli di controllo OpenStack, questo può essere trovato in Access and Security> API Accesso> Credenziali.username(obbligatorio): si riferisce al nome utente di un set utente valido in keystone.password(obbligatorio): fa riferimento alla password di un set utente valido in keystone.tenant-id(obbligatorio): usato per specificare l'id del progetto dove si desidera per creare le tue risorse.tenant-name(Opzionale): utilizzato per specificare il nome del progetto in cui si trova vuoi creare le tue risorse.trust-id(Opzionale): utilizzato per specificare l'identificativo del trust da utilizzare autorizzazione. Un trust rappresenta l'autorizzazione di un utente (il fidato) a delegare i ruoli a un altro utente (il trustee) e facoltativamente consentire al trustee per impersonare il fiduciario. I trust disponibili si trovano sotto/v3/OS-TRUST/trustendpoint dell'API Keystone.domain-id(Opzionale): usato per specificare l'id del dominio a cui appartiene l'utente a.domain-name(Opzionale): utilizzato per specificare il nome del dominio dell'utente appartiene a.region(Opzionale): utilizzato per specificare l'identificatore della regione da utilizzare quando in esecuzione su un cloud OpenStack multiregionale. Una regione è una divisione generale di una distribuzione OpenStack. Anche se una regione non ha una geografia rigorosa connotazione, una distribuzione può utilizzare un nome geografico per un identificatore di regione comeus-east. Le regioni disponibili si trovano sotto/v3/regionendpoint dell'API Keystone.ca-file(Opzionale): utilizzato per specificare il percorso del file CA personalizzato.
Quando si usa Keystone V3 - che cambia il titolare del progetto - il valore tenant-id
viene automaticamente associato al costrutto del progetto nell'API.
Load Balancer
Queste opzioni di configurazione per il provider OpenStack riguardano il carico
bilanciamento e dovrebbe apparire nella sezione [LoadBalancer] di cloud.conf
file:
lb-version(Opzionale): usato per sovrascrivere il rilevamento automatico della versione. Valido i valori sonov1ov2. Dove non viene fornito alcun valore, lo sarà il rilevamento automatico seleziona la versione supportata più alta esposta dal sottostante OpenStack nube.use-octavia(Opzionale): utilizzato per determinare se cercare e utilizzare un Octavia LBaaS V2 endpoint del catalogo di servizi. I valori validi sonotrueofalse. Dovetrueè specificato e non è possibile trovare una voce V2 Octaiva LBaaS, il il provider si ritirerà e tenterà di trovare un endpoint Neutron LBaaS V2 anziché. Il valore predefinito èfalse.subnet-id(Opzionale): usato per specificare l'id della sottorete che si desidera crea il tuo loadbalancer su Può essere trovato su Rete> Reti. Clicca sul rispettiva rete per ottenere le sue sottoreti.floating-network-id(Opzionale): se specificato, creerà un IP mobile per il bilanciamento del carico.lb-method(Opzionale): utilizzato per specificare l'algoritmo in base al quale verrà caricato il carico distribuito tra i membri del pool di bilanciamento del carico. Il valore può essereROUND_ROBIN,LEAST_CONNECTIONSoSOURCE_IP. Il comportamento predefinito se nessuno è specificato èROUND_ROBIN.lb-provider(Opzionale): utilizzato per specificare il provider del servizio di bilanciamento del carico. Se non specificato, sarà il servizio provider predefinito configurato in neutron Usato.create-monitor(Opzionale): indica se creare o meno una salute monitorare il bilanciamento del carico Neutron. I valori validi sonotrueefalse. L'impostazione predefinita èfalse. Quando è specificatotruequindimonitor-delay,monitor-timeout, emonitor-max-retriesdeve essere impostato.monitor-delay(Opzionale): il tempo tra l'invio delle sonde a membri del servizio di bilanciamento del carico. Assicurati di specificare un'unità di tempo valida. Le unità di tempo valide sono "ns", "us" (o "μs"), "ms", "s", "m", "h"monitor-timeout(Opzionale): tempo massimo di attesa per un monitor per una risposta ping prima che scada. Il valore deve essere inferiore al ritardo valore. Assicurati di specificare un'unità di tempo valida. Le unità di tempo valide sono "ns", "us" (o "μs"), "ms", "s", "m", "h"monitor-max-retries(Opzionale): numero di errori ping consentiti prima cambiare lo stato del membro del bilanciamento del carico in INATTIVO. Deve essere un numero tra 1 e 10.manage-security-groups(Opzionale): Determina se il carico è o meno il sistema di bilanciamento dovrebbe gestire automaticamente le regole del gruppo di sicurezza. Valori validi sonotrueefalse. L'impostazione predefinita èfalse. Quando è specificatotruenode-security-groupdeve anche essere fornito.node-security-group(Opzionale): ID del gruppo di sicurezza da gestire.
Block Storage
Queste opzioni di configurazione per il provider OpenStack riguardano lo storage a blocchi
e dovrebbe apparire nella sezione [BlockStorage] del file cloud.conf:
bs-version(Opzionale): usato per sovrascrivere il rilevamento automatico delle versioni. Valido i valori sonov1,v2,v3eauto. Quandoautoè specificato automatico il rilevamento selezionerà la versione supportata più alta esposta dal sottostante Cloud OpenStack. Il valore predefinito se nessuno è fornito èauto.trust-device-path(Opzionale): Nella maggior parte degli scenari i nomi dei dispositivi a blocchi fornito da Cinder (ad esempio/dev/vda) non può essere considerato attendibile. Questo commutatore booleano questo comportamento Impostandolo sutruerisulta fidarsi dei nomi dei dispositivi a blocchi fornito da Cinder. Il valore predefinito difalserisulta nella scoperta di il percorso del dispositivo in base al suo numero di serie e mappatura/dev/disk/by-ided è l'approccio raccomandatoignore-volume-az(Opzionale): usato per influenzare l'uso della zona di disponibilità quando allegando i volumi di Cinder. Quando Nova e Cinder hanno una diversa disponibilità zone, questo dovrebbe essere impostato sutrue. Questo è più comunemente il caso in cui ci sono molte zone di disponibilità Nova ma solo una zona di disponibilità Cinder. Il valore predefinito èfalseper preservare il comportamento utilizzato in precedenza rilasci, ma potrebbero cambiare in futuro.
Se si distribuiscono le versioni di Kubernetes <= 1.8 su una distribuzione OpenStack che utilizza
percorsi piuttosto che porte per distinguere tra endpoint potrebbe essere necessario
per impostare in modo esplicito il parametro bs-version. Un endpoint basato sul percorso è del
forma http://foo.bar/ volume mentre un endpoint basato sulla porta è del modulo
Http://foo.bar: xxx.
In ambienti che utilizzano endpoint basati sul percorso e Kubernetes utilizza il precedente logica di auto-rilevamento un errore dell'autodeterminazione della versione API BS non riuscito. Errore restituito al tentativo di distacco del volume. Per risolvere questo problema lo è possibile forzare l'uso dell'API di Cinder versione 2 aggiungendo questo al cloud configurazione del provider:
[BlockStorage]
bs-version=v2
Metadata
Queste opzioni di configurazione per il provider OpenStack riguardano i metadati e
dovrebbe apparire nella sezione [Metadata] del file cloud.conf:
ricerca-ordine(facoltativo): questo tasto di configurazione influenza il modo in cui il il provider recupera i metadati relativi alle istanze in cui viene eseguito. Il il valore predefinito diconfigDrive, metadataServicerisulta nel provider recuperare i metadati relativi all'istanza dall'unità di configurazione prima se disponibile e quindi il servizio di metadati. I valori alternativi sono: *configDrive- recupera solo i metadati dell'istanza dalla configurazione guidare. *metadataService: recupera solo i metadati dell'istanza dai metadati servizio. *metadataService, configDrive- Recupera i metadati dell'istanza dai metadati prima assistenza se disponibile, quindi l'unità di configurazione.
Influenzare questo comportamento può essere desiderabile come i metadati sul l'unità di configurazione può diventare obsoleta nel tempo, mentre il servizio di metadati fornisce sempre la vista più aggiornata. Non tutti i cloud di OpenStack forniscono sia l'unità di configurazione che il servizio di metadati e solo l'uno o l'altro potrebbe essere disponibile, motivo per cui l'impostazione predefinita è controllare entrambi.
Router
Queste opzioni di configurazione per il provider OpenStack riguardano kubenet
Il plugin di rete di Kubernetes dovrebbe apparire nella sezione [Router] di
File cloud.conf:
router-id(opzionale): se supporta la distribuzione Neutron del cloud sottostante l'estensioneextraroutesquindi usarouter-idper specificare un router da aggiungere percorsi per. Il router scelto deve estendersi alle reti private che contengono il tuo nodi del cluster (in genere esiste solo una rete di nodi e questo valore dovrebbe essere il router predefinito per la rete di nodi). Questo valore è necessario per utilizzare kubenet su OpenStack.
OVirt
Node Name
Il provider di cloud OVirt utilizza il nome host del nodo (come determinato dal kubelet o sovrascritto
con --hostname-override) come nome dell'oggetto Nodo Kubernetes. Si noti che il nome del nodo Kubernetes deve
corrispondere al FQDN del VM (riportato da OVirt in <vm> <guest_info> <fqdn> ... </fqdn> </guest_info> </vm>)
Photon
Node Name
Il provider cloud Photon utilizza il nome host del nodo (come determinato dal kubelet o sovrascritto
con --hostname-override) come nome dell'oggetto Nodo Kubernetes. Si noti che il nome del nodo Kubernetes deve
corrispondere al nome VM Photon (o se "overrideIP è impostato su true in --cloud-config`, il nome del nodo Kubernetes
deve corrispondere all'indirizzo IP della macchina virtuale Photon).
VSphere
Node Name
Il provider cloud VSphere utilizza il nome host rilevato del nodo (come determinato dal kubelet) come nome dell'oggetto Nodo Kubernetes.
Il parametro --hostname-override viene ignorato dal fornitore di cloud VSphere.
IBM Cloud Kubernetes Service
Compute nodes
Utilizzando il provider di servizi IBM Cloud Kubernetes, è possibile creare cluster con una combinazione di nodi virtuali e fisici (bare metal) in una singola zona o su più zone in una regione. Per ulteriori informazioni, consultare Pianificazione dell'installazione di cluster e nodo di lavoro.
Il nome dell'oggetto Nodo Kubernetes è l'indirizzo IP privato dell'istanza del nodo di lavoro IBM Cloud Kubernetes Service.
Networking
Il fornitore di servizi IBM Cloud Kubernetes fornisce VLAN per le prestazioni di rete di qualità e l'isolamento della rete per i nodi. È possibile configurare firewall personalizzati e criteri di rete Calico per aggiungere un ulteriore livello di sicurezza per il cluster o per connettere il cluster al data center on-prem tramite VPN. Per ulteriori informazioni, vedere Pianificazione in-cluster e rete privata.
Per esporre le app al pubblico o all'interno del cluster, è possibile sfruttare i servizi NodePort, LoadBalancer o Ingress. È anche possibile personalizzare il bilanciamento del carico dell'applicazione Ingress con le annotazioni. Per ulteriori informazioni, vedere Pianificazione per esporre le app con reti esterne.
Storage
Il fornitore di servizi IBM Cloud Kubernetes sfrutta i volumi persistenti nativi di Kubernetes per consentire agli utenti di montare archiviazione di file, blocchi e oggetti cloud nelle loro app. È inoltre possibile utilizzare il componente aggiuntivo database-as-a-service e di terze parti per la memorizzazione permanente dei dati. Per ulteriori informazioni, vedere Pianificazione dell'archiviazione persistente altamente disponibile.
Baidu Cloud Container Engine
Node Name
Il provider di cloud Baidu utilizza l'indirizzo IP privato del nodo (come determinato dal kubelet o sovrascritto
con --hostname-override) come nome dell'oggetto Nodo Kubernetes. Si noti che il nome del nodo Kubernetes deve
corrispondere all'IP privato VM di Baidu.
4 - Gestione delle risorse
Hai distribuito la tua applicazione e l'hai esposta tramite un servizio. Ora cosa? Kubernetes fornisce una serie di strumenti per aiutarti a gestire la distribuzione delle applicazioni, compreso il ridimensionamento e l'aggiornamento. Tra le caratteristiche che discuteremo in modo più approfondito ci sono file di configurazione e labels.
Organizzazione delle configurazioni delle risorse
Molte applicazioni richiedono la creazione di più risorse, ad esempio una distribuzione e un servizio. La gestione di più risorse può essere semplificata raggruppandole nello stesso file (separate da --- in YAML). Per esempio:
apiVersion: v1
kind: Service
metadata:
name: my-nginx-svc
labels:
app: nginx
spec:
type: LoadBalancer
ports:
- port: 80
selector:
app: nginx
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-nginx
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
Multiple resources can be created the same way as a single resource:
$ kubectl create -f https://k8s.io/examples/application/nginx-app.yaml
service/my-nginx-svc created
deployment.apps/my-nginx created
Le risorse verranno create nell'ordine in cui appaiono nel file. Pertanto, è meglio specificare prima il servizio, poiché ciò assicurerà che lo scheduler possa distribuire i pod associati al servizio man mano che vengono creati dal / i controller, ad esempio Deployment.
kubectl create accetta anche più argomenti -f:
$ kubectl create -f https://k8s.io/examples/application/nginx/nginx-svc.yaml -f https://k8s.io/examples/application/nginx/nginx-deployment.yaml
E una directory può essere specificata piuttosto che o in aggiunta ai singoli file:
$ kubectl create -f https://k8s.io/examples/application/nginx/
kubectl leggerà tutti i file con suffissi .yaml, .yml o .json.
Si consiglia di inserire nello stesso file risorse correlate allo stesso livello di microservice o di applicazione e di raggruppare tutti i file associati all'applicazione nella stessa directory. Se i livelli dell'applicazione si associano tra loro tramite DNS, è quindi possibile distribuire in massa tutti i componenti dello stack.
Un URL può anche essere specificato come origine di configurazione, utile per la distribuzione direttamente dai file di configurazione controllati in github:
$ kubectl create -f https://raw.githubusercontent.com/kubernetes/website/master/content/en/examples/application/nginx/nginx-deployment.yaml
deployment.apps/my-nginx created
Bulk operations in kubectl
La creazione di risorse non è l'unica operazione che kubectl può eseguire alla rinfusa. Può anche estrarre i nomi delle risorse dai file di configurazione per eseguire altre operazioni, in particolare per eliminare le stesse risorse che hai creato:
$ kubectl delete -f https://k8s.io/examples/application/nginx-app.yaml
deployment.apps "my-nginx" deleted
service "my-nginx-svc" deleted
Nel caso di due sole risorse, è anche facile specificare entrambi sulla riga di comando usando la sintassi risorsa / nome:
$ kubectl delete deployments/my-nginx services/my-nginx-svc
Per un numero maggiore di risorse, troverai più semplice specificare il selettore (query etichetta) specificato usando -l o --selector, per filtrare le risorse in base alle loro etichette:
$ kubectl delete deployment,services -l app=nginx
deployment.apps "my-nginx" deleted
service "my-nginx-svc" deleted
130/5000
Poiché kubectl restituisce i nomi delle risorse nella stessa sintassi che accetta, è facile concatenare le operazioni usando$ ()o xargs:
$ kubectl get $(kubectl create -f docs/concepts/cluster-administration/nginx/ -o name | grep service)
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
my-nginx-svc LoadBalancer 10.0.0.208 <pending> 80/TCP 0s
Con i suddetti comandi, prima creiamo le risorse sotto examples/application/nginx/ e stampiamo le risorse create con il formato di output -o name
(stampa ogni risorsa come risorsa / nome). Quindi grep solo il" servizio ", e poi lo stampiamo con kubectl get.
Se si organizzano le risorse su più sottodirectory all'interno di una particolare directory, è possibile eseguire ricorsivamente anche le operazioni nelle sottodirectory, specificando --recursive o -R accanto al flag --filename, -f.
Ad esempio, supponiamo che ci sia una directory project/k8s/development che contiene tutti i manifesti necessari per l'ambiente di sviluppo, organizzati per tipo di risorsa:
project/k8s/development
├── configmap
│ └── my-configmap.yaml
├── deployment
│ └── my-deployment.yaml
└── pvc
└── my-pvc.yaml
Per impostazione predefinita, l'esecuzione di un'operazione bulk su project/k8s/development si interromperà al primo livello della directory, senza elaborare alcuna sottodirectory. Se avessimo provato a creare le risorse in questa directory usando il seguente comando, avremmo riscontrato un errore:
$ kubectl create -f project/k8s/development
error: you must provide one or more resources by argument or filename (.json|.yaml|.yml|stdin)
Invece, specifica il flag --recursive o -R con il flag --filename, -f come tale:
$ kubectl create -f project/k8s/development --recursive
configmap/my-config created
deployment.apps/my-deployment created
persistentvolumeclaim/my-pvc created
Il flag --recursive funziona con qualsiasi operazione che accetta il flag --filename, -f come: kubectl {crea, ottieni, cancella, descrivi, implementa} ecc .
Il flag --recursive funziona anche quando sono forniti più argomenti -f:
$ kubectl create -f project/k8s/namespaces -f project/k8s/development --recursive
namespace/development created
namespace/staging created
configmap/my-config created
deployment.apps/my-deployment created
persistentvolumeclaim/my-pvc created
Se sei interessato a saperne di più su kubectl, vai avanti e leggi Panoramica di kubectl.
Usare le etichette in modo efficace
Gli esempi che abbiamo utilizzato fino ad ora si applicano al massimo una singola etichetta a qualsiasi risorsa. Esistono molti scenari in cui è necessario utilizzare più etichette per distinguere i set l'uno dall'altro.
Ad esempio, diverse applicazioni utilizzerebbero valori diversi per l'etichetta app, ma un'applicazione multilivello, come l'esempio guestbook, avrebbe inoltre bisogno di distinguere ogni livello. Il frontend potrebbe contenere le seguenti etichette:
labels:
app: guestbook
tier: frontend
while the Redis master and slave would have different tier labels, and perhaps even an additional role label:
labels:
app: guestbook
tier: backend
role: master
and
labels:
app: guestbook
tier: backend
role: slave
Le etichette ci permettono di tagliare e tagliare le nostre risorse lungo qualsiasi dimensione specificata da un'etichetta:
$ kubectl create -f examples/guestbook/all-in-one/guestbook-all-in-one.yaml
$ kubectl get pods -Lapp -Ltier -Lrole
NAME READY STATUS RESTARTS AGE APP TIER ROLE
guestbook-fe-4nlpb 1/1 Running 0 1m guestbook frontend <none>
guestbook-fe-ght6d 1/1 Running 0 1m guestbook frontend <none>
guestbook-fe-jpy62 1/1 Running 0 1m guestbook frontend <none>
guestbook-redis-master-5pg3b 1/1 Running 0 1m guestbook backend master
guestbook-redis-slave-2q2yf 1/1 Running 0 1m guestbook backend slave
guestbook-redis-slave-qgazl 1/1 Running 0 1m guestbook backend slave
my-nginx-divi2 1/1 Running 0 29m nginx <none> <none>
my-nginx-o0ef1 1/1 Running 0 29m nginx <none> <none>
$ kubectl get pods -lapp=guestbook,role=slave
NAME READY STATUS RESTARTS AGE
guestbook-redis-slave-2q2yf 1/1 Running 0 3m
guestbook-redis-slave-qgazl 1/1 Running 0 3m
Distribuzioni canarie
Un altro scenario in cui sono necessarie più etichette è quello di distinguere distribuzioni di diverse versioni o configurazioni dello stesso componente. È prassi comune distribuire un * canarino * di una nuova versione dell'applicazione (specificata tramite il tag immagine nel modello pod) parallelamente alla versione precedente in modo che la nuova versione possa ricevere il traffico di produzione in tempo reale prima di distribuirlo completamente.
Ad esempio, puoi usare un'etichetta track per differenziare le diverse versioni.
La versione stabile e primaria avrebbe un'etichetta track con valore come stable:
name: frontend
replicas: 3
...
labels:
app: guestbook
tier: frontend
track: stable
...
image: gb-frontend:v3
e quindi puoi creare una nuova versione del frontend del guestbook che porta l'etichetta track con un valore diverso
(ad esempio canary), in modo che due gruppi di pod non si sovrappongano:
name: frontend-canary
replicas: 1
...
labels:
app: guestbook
tier: frontend
track: canary
...
image: gb-frontend:v4
Il servizio di frontend coprirebbe entrambe le serie di repliche selezionando il sottoinsieme comune delle loro
etichette (ad esempio omettendo l'etichetta track), in modo che il traffico venga reindirizzato ad entrambe le
applicazioni:
selector:
app: guestbook
tier: frontend
452/5000 È possibile modificare il numero di repliche delle versioni stable e canary per determinare il rapporto tra ciascuna versione che riceverà il traffico di produzione live (in questo caso, 3: 1). Una volta che sei sicuro, puoi aggiornare la traccia stabile alla nuova versione dell'applicazione e rimuovere quella canarino.
Per un esempio più concreto, controlla il tutorial di distribuzione di Ghost.
Updating labels
A volte i pod esistenti e altre risorse devono essere rinominati prima di creare nuove risorse. Questo può essere fatto
con l'etichetta kubectl. Ad esempio, se desideri etichettare tutti i tuoi pod nginx come livello frontend, esegui
semplicemente:
$ kubectl label pods -l app=nginx tier=fe
pod/my-nginx-2035384211-j5fhi labeled
pod/my-nginx-2035384211-u2c7e labeled
pod/my-nginx-2035384211-u3t6x labeled
Questo prima filtra tutti i pod con l'etichetta "app = nginx", quindi li etichetta con il "tier = fe". Per vedere i pod appena etichettati, esegui:
$ kubectl get pods -l app=nginx -L tier
NAME READY STATUS RESTARTS AGE TIER
my-nginx-2035384211-j5fhi 1/1 Running 0 23m fe
my-nginx-2035384211-u2c7e 1/1 Running 0 23m fe
my-nginx-2035384211-u3t6x 1/1 Running 0 23m fe
questo produce tutti i pod "app = nginx", con un'ulteriore colonna di etichette del livello dei pod (specificata
con -L o --label-columns).
Per ulteriori informazioni, consultare labels e kubectl label.
Aggiornare annotazioni
A volte vorresti allegare annotazioni alle risorse. Le annotazioni sono metadati arbitrari non identificativi per il
recupero da parte di client API come strumenti, librerie, ecc. Questo può essere fatto con kubectl annotate. Per
esempio:
$ kubectl annotate pods my-nginx-v4-9gw19 description='my frontend running nginx'
$ kubectl get pods my-nginx-v4-9gw19 -o yaml
apiversion: v1
kind: pod
metadata:
annotations:
description: my frontend running nginx
...
Per ulteriori informazioni, consultare il documento annotazioni e kubectl annotate.
Ridimensionamento dell'applicazione
Quando si carica o si riduce la richiesta, è facile ridimensionare con kubectl. Ad esempio, per ridurre il numero di
repliche nginx da 3 a 1, fare:
$ kubectl scale deployment/my-nginx --replicas=1
deployment.apps/my-nginx scaled
Ora hai solo un pod gestito dalla distribuzione
$ kubectl get pods -l app=nginx
NAME READY STATUS RESTARTS AGE
my-nginx-2035384211-j5fhi 1/1 Running 0 30m
Per fare in modo che il sistema scelga automaticamente il numero di repliche nginx secondo necessità, da 1 a 3, fare:
$ kubectl autoscale deployment/my-nginx --min=1 --max=3
horizontalpodautoscaler.autoscaling/my-nginx autoscaled
Ora le repliche di nginx verranno ridimensionate automaticamente in base alle esigenze.
Per maggiori informazioni, vedi scala kubectl, kubectl autoscale e documento orizzontale pod autoscaler.
Aggiornamenti sul posto delle risorse
A volte è necessario apportare aggiornamenti stretti e senza interruzioni alle risorse che hai creato.
kubectl apply
Si consiglia di mantenere un set di file di configurazione nel controllo del codice sorgente (vedere
configurazione come codice), in modo che possano essere
mantenuti e versionati insieme al codice per le risorse che configurano. Quindi, puoi usare
kubectl apply per inviare le modifiche alla configurazione
nel cluster.
Questo comando confronterà la versione della configurazione che stai spingendo con la versione precedente e applicherà le modifiche che hai apportato, senza sovrascrivere le modifiche automatiche alle proprietà che non hai specificato.
$ kubectl apply -f https://k8s.io/examples/application/nginx/nginx-deployment.yaml
deployment.apps/my-nginx configured
Si noti che kubectl apply allega un'annotazione alla risorsa per determinare le modifiche alla configurazione
dall'invocazione precedente. Quando viene invocato, kubectl apply fa una differenza a tre tra la configurazione
precedente, l'input fornito e la configurazione corrente della risorsa, al fine di determinare come modificare la
risorsa.
Attualmente, le risorse vengono create senza questa annotazione, quindi la prima chiamata di kubectl apply ricadrà su
una differenza a due vie tra l'input fornito e la configurazione corrente della risorsa. Durante questa prima chiamata,
non è in grado di rilevare l'eliminazione delle proprietà impostate al momento della creazione della risorsa. Per questo
motivo, non li rimuoverà.
Tutte le chiamate successive a kubectl apply, e altri comandi che modificano la configurazione, come kubectl replace
e kubectl edit, aggiorneranno l'annotazione, consentendo le successive chiamate a kubectl apply per rilevare ed
eseguire cancellazioni usando un tre via diff.
Nota:
To use apply, always create resource initially with eitherkubectl apply or kubectl create --save-config.kubectl edit
In alternativa, puoi anche aggiornare le risorse con kubectl edit:
$ kubectl edit deployment/my-nginx
Questo equivale a prima get la risorsa, modificarla nell'editor di testo e quindi apply la risorsa con la
versione aggiornata:
$ kubectl get deployment my-nginx -o yaml > /tmp/nginx.yaml
$ vi /tmp/nginx.yaml
# do some edit, and then save the file
$ kubectl apply -f /tmp/nginx.yaml
deployment.apps/my-nginx configured
$ rm /tmp/nginx.yaml
Questo ti permette di fare più cambiamenti significativi più facilmente. Nota che puoi specificare l'editor con le
variabili di ambiente EDITOR o KUBE_EDITOR.
Per ulteriori informazioni, consultare il documento kubectl edit.
kubectl patch
You can use kubectl patch to update API objects in place. This command supports JSON patch,
JSON merge patch, and strategic merge patch. See
Update API Objects in Place Using kubectl patch
and
kubectl patch.
Disruptive updates
375/5000
In alcuni casi, potrebbe essere necessario aggiornare i campi di risorse che non possono essere aggiornati una volta
inizializzati, oppure si può semplicemente voler fare immediatamente una modifica ricorsiva, come per esempio correggere
i pod spezzati creati da una distribuzione. Per cambiare tali campi, usa replace --force, che elimina e ricrea la
risorsa. In questo caso, puoi semplicemente modificare il tuo file di configurazione originale:
$ kubectl replace -f https://k8s.io/examples/application/nginx/nginx-deployment.yaml --force
deployment.apps/my-nginx deleted
deployment.apps/my-nginx replaced
Aggiornamento dell'applicazione senza un'interruzione del servizio
A un certo punto, alla fine sarà necessario aggiornare l'applicazione distribuita, in genere specificando una nuova
immagine o un tag immagine, come nello scenario di distribuzione canarino precedente. kubectl supporta diverse
operazioni di aggiornamento, ognuna delle quali è applicabile a diversi scenari.
Ti guideremo attraverso come creare e aggiornare le applicazioni con le distribuzioni. Se l'applicazione distribuita è
gestita dai controller di replica, dovresti leggere
come usare kubectl rolling-update.
Diciamo che stavi usando la versione 1.7.9 di nginx:
$ kubectl run my-nginx --image=nginx:1.7.9 --replicas=3
deployment.apps/my-nginx created
Per aggiornare alla versione 1.9.1, cambia semplicemente .spec.template.spec.containers [0] .image da nginx: 1.7.9
a nginx: 1.9.1, con i comandi kubectl che abbiamo imparato sopra.
$ kubectl edit deployment/my-nginx
Questo è tutto! La distribuzione aggiornerà in modo dichiarativo l'applicazione nginx distribuita progressivamente dietro la scena. Garantisce che solo un certo numero di vecchie repliche potrebbe essere inattivo mentre vengono aggiornate e solo un certo numero di nuove repliche può essere creato sopra il numero desiderato di pod. Per ulteriori informazioni su di esso, visitare Pagina di distribuzione.
Voci correlate
5 - Cluster Networking
Il networking è una parte centrale di Kubernetes, ma può essere difficile capire esattamente come dovrebbe funzionare. Ci sono 4 reti distinte problemi da affrontare:
- Comunicazioni container-to-container altamente accoppiate: questo è risolto da
pod e comunicazioni
localhost. - Comunicazioni Pod-to-Pod: questo è l'obiettivo principale di questo documento.
- Comunicazioni Pod-to-Service: questo è coperto da servizi.
- Comunicazioni da esterno a servizio: questo è coperto da servizi.
Kubernetes è tutto basato sulla condivisione di macchine tra le applicazioni. Tipicamente, la condivisione di macchine richiede che due applicazioni non provino a utilizzare il stesse porte. È molto difficile coordinare le porte tra più sviluppatori fare su larga scala ed esporre gli utenti a problemi a livello di cluster al di fuori del loro controllo.
L'allocazione dinamica delle porte apporta molte complicazioni al sistema: tutte l'applicazione deve prendere le porte come flag, i server API devono sapere come inserire numeri di porta dinamici in blocchi di configurazione, i servizi devono sapere come trovarsi, ecc. Piuttosto che occuparsene, Kubernetes prende un approccio diverso.
Il modello di rete di Kubernetes
Ogni Pod ottiene il proprio indirizzo IP. Ciò significa che non è necessario esplicitamente
crea collegamenti tra Pod 'e non hai quasi mai bisogno di gestire la mappatura porte del contenitore per ospitare le porte. Questo crea un pulito, retrocompatibile modello in cui Pods` può essere trattato in modo molto simile a VM o host fisici da
prospettive di allocazione delle porte, denominazione, individuazione dei servizi, bilanciamento del carico,
configurazione dell'applicazione e migrazione.
Kubernetes impone i seguenti requisiti fondamentali su qualsiasi rete implementazione (salvo eventuali politiche di segmentazione di rete intenzionale):
* i pod su un nodo possono comunicare con tutti i pod su tutti i nodi senza NAT * agenti su un nodo (ad esempio i daemon di sistema, kubelet) possono comunicare con tutti pod su quel nodo
Nota: per quelle piattaforme che supportano Pods in esecuzione nella rete host (ad es.
Linux):
* i pod nella rete host di un nodo possono comunicare con tutti i pod su tutti nodi senza NAT
Questo modello non è solo complessivamente meno complesso, ma è principalmente compatibile con il desiderio di Kubernetes di abilitare il porting a bassa frizione di app da VM ai contenitori. Se il tuo lavoro è già stato eseguito in una macchina virtuale, la tua macchina virtuale ha avuto un indirizzo IP e potrebbe parla con altre macchine virtuali nel tuo progetto. Questo è lo stesso modello base.
Gli indirizzi IP di Kubernetes esistono nello scope Pod - contenitori all'interno di un 'Podcondividere i loro spazi dei nomi di rete, compreso il loro indirizzo IP. Ciò significa che i contenitori all'interno di unPodpossono raggiungere tutti gli altri porti sulocalhost. Questo significa anche che i contenitori all'interno di un 'Pod devono coordinare l'utilizzo della porta, ma questo
non è diverso dai processi in una VM. Questo è chiamato il modello "IP-per-pod".
Il modo in cui viene implementato è un dettaglio del particolare runtime del contenitore in uso.
È possibile richiedere le porte sul Node stesso che inoltrerà al tuo 'Pod(chiamate porte host), ma questa è un'operazione molto di nicchia. Come è quella spedizione implementato è anche un dettaglio del runtime del contenitore. IlPod` stesso è
cieco all'esistenza o alla non esistenza dei porti di accoglienza.
Come implementare il modello di rete di Kubernetes
Ci sono diversi modi in cui questo modello di rete può essere implementato. Questo il documento non è uno studio esaustivo dei vari metodi, ma si spera che serva come introduzione a varie tecnologie e serve da punto di partenza.
Le seguenti opzioni di networking sono ordinate alfabeticamente - l'ordine no implica uno stato preferenziale.
ACI
Cisco Application Centric Infrastructure offers an integrated overlay and underlay SDN solution that supports containers, virtual machines, and bare metal servers. ACI provides container networking integration for ACI. An overview of the integration is provided here.
AOS da Apstra
AOS è un sistema di rete basato sull'intento che crea e gestisce ambienti di data center complessi da una semplice piattaforma integrata. AOS sfrutta un design distribuito altamente scalabile per eliminare le interruzioni di rete riducendo al minimo i costi.
Il progetto di riferimento AOS attualmente supporta gli host connessi Layer-3 che eliminano i problemi di commutazione Layer-2 legacy. Questi host Layer-3 possono essere server Linux (Debian, Ubuntu, CentOS) che creano relazioni vicine BGP direttamente con gli switch top of rack (TOR). AOS automatizza le adiacenze di routing e quindi fornisce un controllo a grana fine sulle iniezioni di integrità del percorso (RHI) comuni in una distribuzione di Kubernetes.
AOS dispone di un ricco set di endpoint REST API che consentono a Kubernetes di modificare rapidamente i criteri di rete in base ai requisiti dell'applicazione. Ulteriori miglioramenti integreranno il modello AOS Graph utilizzato per la progettazione della rete con il provisioning del carico di lavoro, consentendo un sistema di gestione end-to-end per cloud privati e pubblici.
AOS supporta l'utilizzo di apparecchiature di produttori comuni di produttori quali Cisco, Arista, Dell, Mellanox, HPE e un gran numero di sistemi white-box e sistemi operativi di rete aperti come Microsoft SONiC, Dell OPX e Cumulus Linux.
I dettagli su come funziona il sistema AOS sono disponibili qui: http://www.apstra.com/products/how-it-works/
Big Cloud Fabric da Big Switch Networks
Big Cloud Fabric è un'architettura di rete nativa cloud, progettata per eseguire Kubernetes in ambienti cloud privati / on-premise. Utilizzando un SDN fisico e virtuale unificato, Big Cloud Fabric affronta problemi intrinseci di rete di container come bilanciamento del carico, visibilità, risoluzione dei problemi, politiche di sicurezza e monitoraggio del traffico container.
Con l'aiuto dell'architettura multi-tenant del pod virtuale di Big Cloud Fabric, i sistemi di orchestrazione di container come Kubernetes, RedHat OpenShift, Mesosphere DC / OS e Docker Swarm saranno integrati nativamente con i sistemi di orchestrazione VM come VMware, OpenStack e Nutanix. I clienti saranno in grado di interconnettere in modo sicuro qualsiasi numero di questi cluster e abilitare la comunicazione tra i titolari, se necessario.
BCF è stato riconosciuto da Gartner come un visionario nell'ultimo Magic Quadrant. Viene anche fatto riferimento a una delle distribuzioni on-premises BCF Kubernetes (che include Kubernetes, DC / OS e VMware in esecuzione su più DC in diverse regioni geografiche) [https://portworx.com/architects-corner-kubernetes-satya -komala-nio /).
Cilium
Cilium è un software open source per fornire e proteggere in modo trasparente la connettività di rete tra le applicazioni contenitori. Cilium è consapevole di L7 / HTTP e può applicare i criteri di rete su L3-L7 utilizzando un modello di sicurezza basato sull'identità che è disaccoppiato dalla rete indirizzamento.
CNI-Genie from Huawei
CNI-Genie è un plugin CNI che consente a Kubernetes di avere simultaneamente accesso a diverse implementazioni del modello di rete Kubernetes in runtime. Ciò include qualsiasi implementazione che funziona come un plugin CNI, come Flannel, Calico, Romana, Weave-net.
CNI-Genie supporta anche assegnando più indirizzi IP a un pod, ciascuno da un diverso plugin CNI.
cni-ipvlan-vpc-k8s
cni-ipvlan-vpc-k8s contiene un set di plugin CNI e IPAM per fornire una semplice, host-local, bassa latenza, alta throughput e stack di rete conforme per Kubernetes in Amazon Virtual Ambienti Private Cloud (VPC) facendo uso di Amazon Elastic Network Interfacce (ENI) e associazione degli IP gestiti da AWS in pod usando il kernel di Linux Driver IPvlan in modalità L2.
I plugin sono progettati per essere semplici da configurare e distribuire all'interno di VPC. Kubelets si avvia e quindi autoconfigura e ridimensiona il loro utilizzo IP secondo necessità senza richiedere le complessità spesso raccomandate della gestione della sovrapposizione reti, BGP, disabilitazione dei controlli sorgente / destinazione o regolazione del percorso VPC tabelle per fornire sottoreti per istanza a ciascun host (che è limitato a 50-100 voci per VPC). In breve, cni-ipvlan-vpc-k8s riduce significativamente il complessità della rete richiesta per implementare Kubernetes su larga scala all'interno di AWS.
Contiv
226/5000 Contiv fornisce un networking configurabile (nativo l3 usando BGP, overlay usando vxlan, classic l2 o Cisco-SDN / ACI) per vari casi d'uso. Contiv è tutto aperto.
Contrail / Tungsten Fabric
Contrail, basato su Tungsten Fabric, è un virtualizzazione della rete e piattaforma di gestione delle policy realmente aperte e multi-cloud. Contrail e Tungsten Fabric sono integrati con vari sistemi di orchestrazione come Kubernetes, OpenShift, OpenStack e Mesos e forniscono diverse modalità di isolamento per macchine virtuali, contenitori / pod e carichi di lavoro bare metal.
DANM
DANM è una soluzione di rete per carichi di lavoro di telco in esecuzione in un cluster Kubernetes. È costituito dai seguenti componenti:
- Un plugin CNI in grado di fornire interfacce IPVLAN con funzionalità avanzate * Un modulo IPAM integrato con la capacità di gestire reti L3 multiple, a livello di cluster e discontinue e fornire uno schema di allocazione IP dinamico, statico o nullo su richiesta * Metaplugin CNI in grado di collegare più interfacce di rete a un contenitore, tramite il proprio CNI o delegando il lavoro a qualsiasi soluzione CNI come SRI-OV o Flannel in parallelo * Un controller Kubernetes in grado di gestire centralmente sia le interfacce VxLAN che VLAN di tutti gli host Kubernetes * Un altro controller di Kubernetes che estende il concetto di rilevamento dei servizi basato sui servizi di Kubernetes per funzionare su tutte le interfacce di rete di un pod
Con questo set di strumenti DANM è in grado di fornire più interfacce di rete separate, la possibilità di utilizzare diversi back-end di rete e funzionalità IPAM avanzate per i pod.
Flannel
Flannel è un overlay molto semplice rete che soddisfa i requisiti di Kubernetes. Molti le persone hanno riportato il successo con Flannel e Kubernetes.
Google Compute Engine (GCE)
Per gli script di configurazione del cluster di Google Compute Engine,
avanzato routing è usato per assegna a ciascuna VM una sottorete
(l'impostazione predefinita è / 24 - 254 IP). Qualsiasi traffico vincolato per questo la sottorete verrà instradata
direttamente alla VM dal fabric di rete GCE. Questo è dentro aggiunta all'indirizzo IP "principale" assegnato alla VM,
a cui è stato assegnato NAT accesso a Internet in uscita. Un bridge linux (chiamato cbr0) è configurato per esistere
su quella sottorete, e viene passato al flag --bridge della finestra mobile.
Docker è avviato con:
DOCKER_OPTS="--bridge=cbr0 --iptables=false --ip-masq=false"
Questo bridge è creato da Kubelet (controllato da --network-plugin = kubenet flag) in base al Nodo .spec.podCIDR.
Docker ora assegna gli IP dal blocco cbr-cidr. I contenitori possono raggiungere l'un l'altro e Nodi sul
ponte cbr0. Questi IP sono tutti instradabili all'interno della rete del progetto GCE.
GCE non sa nulla di questi IP, quindi non lo farà loro per il traffico internet in uscita. Per ottenere ciò viene
utilizzata una regola iptables masquerade (aka SNAT - per far sembrare che i pacchetti provengano dal Node stesso)
traffico che è vincolato per IP al di fuori della rete del progetto GCE (10.0.0.0/8).
iptables -t nat -A POSTROUTING ! -d 10.0.0.0/8 -o eth0 -j MASQUERADE
Infine l'inoltro IP è abilitato nel kernel (quindi il kernel elaborerà pacchetti per contenitori a ponte):
sysctl net.ipv4.ip_forward=1
Il risultato di tutto questo è che tutti i Pods possono raggiungere l'altro e possono uscire
traffico verso internet.
Jaguar
Jaguar è una soluzione open source per la rete di Kubernetes basata su OpenDaylight. Jaguar fornisce una rete overlay utilizzando vxlan e Jaguar. CNIPlugin fornisce un indirizzo IP per pod.
Knitter
363/5000 Knitter è una soluzione di rete che supporta più reti in Kubernetes. Fornisce la capacità di gestione dei titolari e gestione della rete. Knitter include una serie di soluzioni di rete container NFV end-to-end oltre a più piani di rete, come mantenere l'indirizzo IP per le applicazioni, la migrazione degli indirizzi IP, ecc.
Kube-router
430/5000 Kube-router è una soluzione di rete sviluppata appositamente per Kubernetes che mira a fornire alte prestazioni e semplicità operativa. Kube-router fornisce un proxy di servizio basato su Linux LVS / IPVS, una soluzione di rete pod-to-pod basata sul kernel di inoltro del kernel Linux senza sovrapposizioni, e il sistema di sicurezza della politica di rete basato su iptables / ipset.
L2 networks and linux bridging
Se hai una rete L2 "stupida", come un semplice switch in un "bare metal" ambiente, dovresti essere in grado di fare qualcosa di simile alla precedente configurazione GCE. Si noti che queste istruzioni sono state provate solo molto casualmente - a quanto pare lavoro, ma non è stato testato a fondo. Se usi questa tecnica e perfezionare il processo, fatecelo sapere.
Segui la sezione "Con dispositivi Linux Bridge" di questo molto bello tutorial da Lars Kellogg-Stedman.
Multus (a Multi Network plugin)
Multus è un plugin Multi CNI per supportare la funzionalità Multi Networking in Kubernetes utilizzando oggetti di rete basati su CRD in Kubernetes.
Multus supporta tutti i plug-in di riferimento (ad esempio Flannel, DHCP, Macvlan) che implementano le specifiche CNI e i plugin di terze parti (ad esempio Calico, Weave ), Cilium, Contiv). Oltre a ciò, Multus supporta SRIOV, DPDK, OVS- DPDK e VPP carichi di lavoro in Kubernetes con applicazioni cloud native e basate su NFV in Kubernetes.
NSX-T
VMware NSX-T è una piattaforma di virtualizzazione e sicurezza della rete. NSX-T può fornire la virtualizzazione di rete per un ambiente multi-cloud e multi-hypervisor ed è focalizzato su architetture applicative emergenti e architetture con endpoint eterogenei e stack tecnologici. Oltre agli hypervisor vSphere, questi ambienti includono altri hypervisor come KVM, container e bare metal.
Plug-in contenitore NSX-T (NCP) fornisce integrazione tra NSX-T e orchestratori di contenitori come Kubernetes, così come l'integrazione tra NSX-T e piattaforme CaaS / PaaS basate su container come Pivotal Container Service (PKS) e OpenShift.
Nuage Networks VCS (Servizi cloud virtualizzati)
Nuage fornisce una piattaforma Software-Defined Networking (SDN) altamente scalabile basata su policy. Nuage utilizza open source Open vSwitch per il piano dati insieme a un controller SDN ricco di funzionalità basato su standard aperti.
La piattaforma Nuage utilizza gli overlay per fornire una rete basata su policy senza soluzione di continuità tra i Pod di Kubernetes e gli ambienti non Kubernetes (VM e server bare metal). Il modello di astrazione delle policy di Nuage è stato progettato pensando alle applicazioni e semplifica la dichiarazione di policy a grana fine per le applicazioni. Il motore di analisi in tempo reale della piattaforma consente la visibilità e il monitoraggio della sicurezza per le applicazioni Kubernetes.
OVN (Apri rete virtuale)
OVN è una soluzione di virtualizzazione della rete opensource sviluppata da Apri la community di vSwitch. Permette di creare switch logici, router logici, ACL di stato, bilanciamento del carico ecc. per costruire reti virtuali diverse topologie. Il progetto ha un plugin e una documentazione specifici per Kubernetes a ovn-kubernetes.
Progetto Calico
Project Calico è un provider di rete contenitore open source e motore di criteri di rete.
Calico offre una soluzione di rete e di rete altamente scalabile per il collegamento di pod Kubernetes basati sugli stessi principi di rete IP di Internet, sia per Linux (open source) che per Windows (proprietario - disponibile da Tigera). Calico può essere distribuito senza incapsulamento o sovrapposizioni per fornire reti di data center ad alte prestazioni e su vasta scala. Calico fornisce inoltre una politica di sicurezza di rete basata su intere grane per i pod Kubernetes tramite il firewall distribuito.
Calico può anche essere eseguito in modalità di applicazione della policy insieme ad altre soluzioni di rete come Flannel, alias canal o native GCE, AWS o networking Azure.
Romana
Romana è una soluzione di automazione della sicurezza e della rete open source che consente di distribuire Kubernetes senza una rete di overlay. Romana supporta Kubernetes Politica di rete per fornire isolamento tra gli spazi dei nomi di rete.
Weave Net di Weaveworks
Weave Net è un rete resiliente e semplice da usare per Kubernetes e le sue applicazioni in hosting. Weave Net funziona come un plug-in CNI o stand-alone. In entrambe le versioni, non richiede alcuna configurazione o codice aggiuntivo per eseguire, e in entrambi i casi, la rete fornisce un indirizzo IP per pod, come è standard per Kubernetes.
Voci correlate
Il progetto iniziale del modello di rete e la sua logica, e un po 'di futuro i piani sono descritti in maggior dettaglio nella progettazione della rete documento.
6 - Log di registrazione
I log di applicazioni e sistemi possono aiutarti a capire cosa sta accadendo all'interno del tuo cluster. I log sono particolarmente utili per il debug dei problemi e il monitoraggio delle attività del cluster. La maggior parte delle applicazioni moderne ha una sorta di meccanismo di registrazione; in quanto tale, la maggior parte dei motori di container sono progettati allo stesso modo per supportare alcuni tipi di registrazione. Il metodo di registrazione più semplice e più accettato per le applicazioni containerizzate è scrivere sull'output standard e sui flussi di errore standard.
Tuttavia, la funzionalità nativa fornita da un motore contenitore o dal runtime di solito non è sufficiente per una soluzione di registrazione completa. Ad esempio, se un container si arresta in modo anomalo, un pod viene rimosso, o un nodo muore, di solito vuoi comunque accedere ai log dell'applicazione. Pertanto, i registri devono avere una memoria e un ciclo di vita separati, indipendenti da nodi, pod o contenitori. Questo concetto è chiamato cluster-logging. La registrazione a livello di cluster richiede un back-end separato per archiviare, analizzare e interrogare i registri. Kubernetes non fornisce alcuna soluzione di archiviazione nativa per i dati di registro, ma è possibile integrare molte soluzioni di registrazione esistenti nel proprio cluster Kubernetes.
Le architetture di registrazione a livello di cluster sono descritte nel presupposto che un back-end per la registrazione è presente all'interno o all'esterno del cluster. Se tu sei non interessa avere la registrazione a livello di cluster, potresti ancora trovarlo la descrizione di come i registri sono memorizzati e gestiti sul nodo per essere utile.
Basic logging in Kubernetes
In questa sezione, puoi vedere un esempio di registrazione di base in Kubernetes emette i dati sul flusso di output standard. Utilizza questa dimostrazione una specifica pod con un contenitore che scrive del testo sullo standard output una volta al secondo.
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox
args: [/bin/sh, -c,
'i=0; while true; do echo "$i: $(date)"; i=$((i+1)); sleep 1; done']
Per eseguire questo pod, utilizzare il seguente comando:
$ kubectl create -f https://k8s.io/examples/debug/counter-pod.yaml
pod/counter created
Per recuperare i registri, usa il comando kubectl logs, come segue:
$ kubectl logs counter
0: Mon Jan 1 00:00:00 UTC 2001
1: Mon Jan 1 00:00:01 UTC 2001
2: Mon Jan 1 00:00:02 UTC 2001
...
You can use kubectl logs to retrieve logsPuoi usare kubectl logs per recuperare i log da una precedente istanziazione di un contenitore con il flag --previous, nel caso in cui il contenitore si sia arrestato in modo anomalo. Se il pod ha più contenitori, è necessario specificare i registri del contenitore a cui si desidera accedere aggiungendo un nome contenitore al comando. Vedi la documentazione kubectl logs per maggiori dettagli. from a previous instantiation of a container with --previous flag, in case the container has crashed. If your pod has multiple containers, you should specify which container's logs you want to access by appending a container name to the command. See the kubectl logs documentation for more details.
Logging at the node level
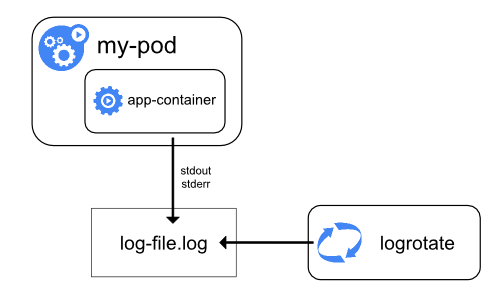{kind=link}
Tutto ciò che una applicazione containerizzata scrive su stdout e stderr viene gestito e reindirizzato da qualche parte da un motore contenitore. Ad esempio, il motore del contenitore Docker reindirizza questi due flussi a un driver di registrazione, che è configurato in Kubernetes per scrivere su un file in formato json .
Nota:
Il driver di registrazione di Docker json considera ogni riga come un messaggio separato. Quando si utilizza il driver di registrazione di Docker, non esiste un supporto diretto per i messaggi su più righe. È necessario gestire i messaggi multilinea a livello di agente di registrazione o superiore.Di default, se un container si riavvia, kubelet mantiene un container terminato con i suoi log. Se un pod viene espulso dal nodo, tutti i contenitori corrispondenti vengono espulsi, insieme ai loro log.
Una considerazione importante nella registrazione a livello di nodo sta implementando la rotazione dei log,
in modo che i registri non consumino tutta la memoria disponibile sul nodo. kubernetes
al momento non è responsabile della rotazione dei registri, ma piuttosto di uno strumento di distribuzione
dovrebbe creare una soluzione per affrontarlo.
Ad esempio, nei cluster di Kubernetes, implementato dallo script kube-up.sh,
c'è un logrotate
strumento configurato per funzionare ogni ora. È anche possibile impostare un runtime del contenitore su
ruotare automaticamente i registri dell'applicazione, ad es. usando il log-opt di Docker.
Nello script kube-up.sh, quest'ultimo approccio viene utilizzato per l'immagine COS su GCP,
e il primo approccio è usato in qualsiasi altro ambiente. In entrambi i casi, da
la rotazione predefinita è configurata per essere eseguita quando il file di registro supera 10 MB.
Ad esempio, puoi trovare informazioni dettagliate su come kube-up.sh imposta
up logging per l'immagine COS su GCP nello [script] cosConfigureHelper corrispondente.
Quando esegui kubectl logs come in
l'esempio di registrazione di base, il kubelet sul nodo gestisce la richiesta e
legge direttamente dal file di log, restituendo il contenuto nella risposta.
Nota:
Attualmente, se un sistema esterno ha eseguito la rotazione, sarà disponibile solo il contenuto dell'ultimo file di registrolog di kubectl. Per esempio. se c'è un file da 10 MB, esegue logrotate
la rotazione e ci sono due file, uno da 10 MB e uno vuoto,
kubectl logs restituirà una risposta vuota.System component logs
Esistono due tipi di componenti di sistema: quelli che vengono eseguiti in un contenitore e quelli che non funziona in un contenitore. Per esempio:
- Lo scheduler di Kubernetes e il proxy kube vengono eseguiti in un contenitore.
- Il kubelet e il runtime del contenitore, ad esempio Docker, non vengono eseguiti nei contenitori.
Sulle macchine con systemd, il kubelet e il runtime del contenitore scrivono su journal. Se
systemd non è presente, scrive nei file .log nella directory/var/log.
I componenti di sistema all'interno dei contenitori scrivono sempre nella directory /var/log,
bypassando il meccanismo di registrazione predefinito. Usano il klog klog
biblioteca di registrazione. È possibile trovare le convenzioni per la gravità della registrazione per quelli
componenti nel documento di sviluppo sulla registrazione.
Analogamente ai log del contenitore, i log dei componenti di sistema sono in /var/log
la directory dovrebbe essere ruotata. Nei cluster di Kubernetes allevati da
lo script kube-up.sh, quei log sono configurati per essere ruotati da
lo strumento logrotate al giorno o una volta che la dimensione supera i 100 MB.
Cluster-level logging architectures
Sebbene Kubernetes non fornisca una soluzione nativa per la registrazione a livello di cluster, esistono diversi approcci comuni che è possibile prendere in considerazione. Ecco alcune opzioni:
- Utilizzare un agente di registrazione a livello di nodo che viene eseguito su ogni nodo.
- Includere un contenitore sidecar dedicato per l'accesso a un pod di applicazione.
- Invia i registri direttamente a un back-end dall'interno di un'applicazione.
Using a node logging agent
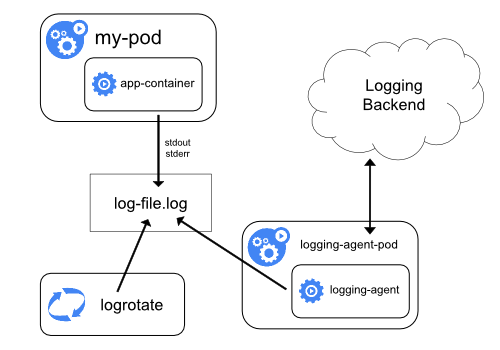
È possibile implementare la registrazione a livello di cluster includendo un agente di registrazione a livello node su ciascun nodo. L'agente di registrazione è uno strumento dedicato che espone i registri o trasferisce i registri a un back-end. Comunemente, l'agente di registrazione è un contenitore che ha accesso a una directory con file di registro da tutti i contenitori delle applicazioni su quel nodo.
Poiché l'agente di registrazione deve essere eseguito su ogni nodo, è comune implementarlo come una replica DaemonSet, un pod manifest o un processo nativo dedicato sul nodo. Tuttavia, questi ultimi due approcci sono deprecati e altamente scoraggiati.
L'utilizzo di un agent di registrazione a livello di nodo è l'approccio più comune e consigliato per un cluster Kubernetes, poiché crea solo un agente per nodo e non richiede alcuna modifica alle applicazioni in esecuzione sul nodo. Tuttavia, la registrazione a livello di nodo funziona solo per l'output standard delle applicazioni e l'errore standard.
Kubernetes non specifica un agente di registrazione, ma due agenti di registrazione facoltativi sono impacchettati con la versione di Kubernetes: Stackdriver Logging da utilizzare con Google Cloud Platform e Elasticsearch. Puoi trovare ulteriori informazioni e istruzioni nei documenti dedicati. Entrambi usano fluentd con configurazione personalizzata come agente sul nodo.
Using a sidecar container with the logging agent
Puoi utilizzare un contenitore sidecar in uno dei seguenti modi:
- Il contenitore sidecar trasmette i log delle applicazioni al proprio
stdout. - Il contenitore sidecar esegue un agente di registrazione, che è configurato per raccogliere i registri da un contenitore di applicazioni.
Streaming sidecar container
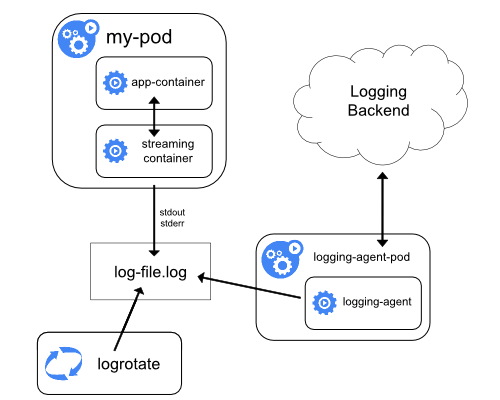
Facendo scorrere i propri contenitori sidecar sul proprio stdout e stderr
flussi, è possibile sfruttare il kubelet e l'agente di registrazione che
già eseguito su ciascun nodo. I contenitori del sidecar leggono i log da un file, un socket,
o il diario. Ogni singolo contenitore sidecar stampa il log nel proprio stdout
o flusso stderr.
Questo approccio consente di separare diversi flussi di log da diversi
parti della tua applicazione, alcune delle quali possono mancare di supporto
per scrivere su stdout o stderr. La logica dietro il reindirizzamento dei registri
è minimo, quindi non è un sovraccarico significativo. Inoltre, perché
stdout e stderr sono gestiti da kubelet, puoi usare gli strumenti integrati
come log di kubectl.
Considera il seguente esempio. Un pod esegue un singolo contenitore e il contenitore scrive su due file di registro diversi, utilizzando due formati diversi. Ecco un file di configurazione per il pod:
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
volumes:
- name: varlog
emptyDir: {}
Sarebbe un disastro avere voci di registro di diversi formati nello stesso registro
stream, anche se si è riusciti a reindirizzare entrambi i componenti al flusso stdout di
Il container. Invece, potresti introdurre due container sidecar. Ogni sidecar
contenitore potrebbe accodare un particolare file di registro da un volume condiviso e quindi reindirizzare
i registri al proprio flusso stdout.
Ecco un file di configurazione per un pod con due contenitori sidecar:
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-log-1
image: busybox
args: [/bin/sh, -c, 'tail -n+1 -f /var/log/1.log']
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-log-2
image: busybox
args: [/bin/sh, -c, 'tail -n+1 -f /var/log/2.log']
volumeMounts:
- name: varlog
mountPath: /var/log
volumes:
- name: varlog
emptyDir: {}
Ora quando si esegue questo pod, è possibile accedere separatamente a ciascun flusso di log eseguendo i seguenti comandi:
$ kubectl logs counter count-log-1
0: Mon Jan 1 00:00:00 UTC 2001
1: Mon Jan 1 00:00:01 UTC 2001
2: Mon Jan 1 00:00:02 UTC 2001
...
$ kubectl logs counter count-log-2
Mon Jan 1 00:00:00 UTC 2001 INFO 0
Mon Jan 1 00:00:01 UTC 2001 INFO 1
Mon Jan 1 00:00:02 UTC 2001 INFO 2
...
L'agente a livello di nodo installato nel cluster preleva tali flussi di log automaticamente senza alcuna ulteriore configurazione. Se ti piace, puoi configurare l'agente per analizzare le righe di registro in base al contenitore di origine.
Si noti che, nonostante il basso utilizzo della CPU e della memoria (ordine di un paio di millesimi
per cpu e ordine di diversi megabyte per memoria), scrivere registri su un file e
quindi il loro streaming su stdout può raddoppiare l'utilizzo del disco. Se hai
un'applicazione che scrive in un singolo file, è generalmente meglio impostare
/dev/stdout come destinazione piuttosto che implementare il sidecar streaming
approccio contenitore.
I contenitori del sidecar possono anche essere usati per ruotare i file di log che non possono essere
ruotato dall'applicazione stessa. Un esempio
di questo approccio è un piccolo contenitore che esegue periodicamente logrotate.
Tuttavia, si raccomanda di usare stdout e stderr direttamente e lasciare la rotazione
e politiche di conservazione al kubelet.
Sidecar container with a logging agent
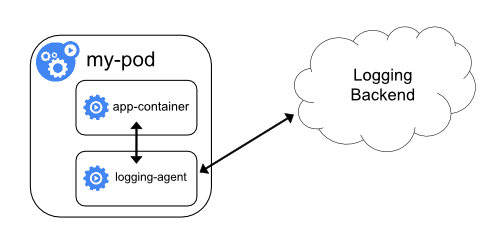
Se l'agente di registrazione a livello di nodo non è abbastanza flessibile per la tua situazione, tu puoi creare un container sidecar con un logger separato che hai configurato specificamente per essere eseguito con la tua applicazione.
Nota:
Può essere utilizzato un agente di registrazione in un container sidecar al consumo significativo di risorse. Inoltre, non sarai in grado di accedere quei log usando il comandokubectl logs, perché non sono controllati
dal kubelet.Ad esempio, è possibile utilizzare Stackdriver, che utilizza fluentd come agente di registrazione. Qui ci sono due file di configurazione puoi usare per implementare questo approccio. Il primo file contiene a ConfigMap per configurare fluentd.
apiVersion: v1
kind: ConfigMap
metadata:
name: fluentd-config
data:
fluentd.conf: |
<source>
type tail
format none
path /var/log/1.log
pos_file /var/log/1.log.pos
tag count.format1
</source>
<source>
type tail
format none
path /var/log/2.log
pos_file /var/log/2.log.pos
tag count.format2
</source>
<match **>
type google_cloud
</match>
Nota:
La configurazione di fluentd esula dallo scopo di questo articolo. Per informazioni sulla configurazione di fluentd, vedere il documentazione fluentd ufficiale.Il secondo file descrive un pod con un contenitore sidecar in esecuzione fluentd. Il pod monta un volume dove fluentd può raccogliere i suoi dati di configurazione.
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-agent
image: registry.k8s.io/fluentd-gcp:1.30
env:
- name: FLUENTD_ARGS
value: -c /etc/fluentd-config/fluentd.conf
volumeMounts:
- name: varlog
mountPath: /var/log
- name: config-volume
mountPath: /etc/fluentd-config
volumes:
- name: varlog
emptyDir: {}
- name: config-volume
configMap:
name: fluentd-config
Dopo un po 'di tempo è possibile trovare i messaggi di registro nell'interfaccia Stackdriver.
Ricorda che questo è solo un esempio e puoi effettivamente sostituire fluentd con qualsiasi agente di registrazione, leggendo da qualsiasi fonte all'interno di un'applicazione contenitore.
Exposing logs directly from the application
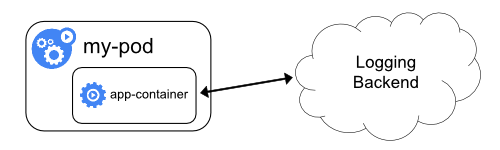
È possibile implementare la registrazione a livello di cluster esponendo o spingendo i registri direttamente da ogni applicazione; tuttavia, l'implementazione di un tale meccanismo di registrazione è al di fuori dello scopo di Kubernetes.
7 - Configurazione della raccolta dati kubelet
La garbage collection è una funzione utile di kubelet che pulisce le immagini inutilizzate e i contenitori inutilizzati. Kubelet eseguirà la raccolta dei rifiuti per i contenitori ogni minuto e la raccolta dei dati inutili per le immagini ogni cinque minuti.
Gli strumenti di garbage collection esterni non sono raccomandati in quanto questi strumenti possono potenzialmente interrompere il comportamento di kubelet rimuovendo i contenitori che si prevede esistano.
Image Collection
Kubernetes gestisce il ciclo di vita di tutte le immagini tramite imageManager, con la collaborazione di consulente.
La politica per la raccolta dei rifiuti delle immagini prende in considerazione due fattori:
HighThresholdPercent e LowThresholdPercent. Utilizzo del disco al di sopra della soglia alta
attiverà la garbage collection. La garbage collection cancellerà le immagini utilizzate meno di recente fino al minimo
soglia è stata soddisfatta.
La politica per la raccolta dei rifiuti delle immagini prende in considerazione due fattori:
HighThresholdPercent e LowThresholdPercent. Utilizzo del disco al di sopra della soglia alta
attiverà la garbage collection. La garbage collection cancellerà le immagini utilizzate meno di recente fino al minimo
soglia è stata soddisfatta.
Container Collection
La politica per i contenitori di garbage collection considera tre variabili definite dall'utente. MinAge è l'età minima
in cui un contenitore può essere raccolto dalla spazzatura. MaxPerPodContainer è il numero massimo di contenitori morti
ogni singolo la coppia pod (UID, nome contenitore) può avere. MaxContainers è il numero massimo di contenitori morti
totali. Queste variabili possono essere disabilitate individualmente impostando MinAge a zero e impostando MaxPerPodContainer
e MaxContainers rispettivamente a meno di zero.
Kubelet agirà su contenitori non identificati, cancellati o al di fuori dei limiti impostati dalle bandiere
precedentemente menzionate. I contenitori più vecchi saranno generalmente rimossi per primi. MaxPerPodContainer
e MaxContainer possono potenzialmente entrare in conflitto l'uno con l'altro in situazioni in cui il mantenimento del
numero massimo di contenitori per pod (MaxPerPodContainer) non rientra nell'intervallo consentito di contenitori morti
globali (MaxContainers). MaxPerPodContainer verrebbe regolato in questa situazione: uno scenario peggiore sarebbe
quello di eseguire il downgrade di MaxPerPodContainer su 1 e rimuovere i contenitori più vecchi. Inoltre, i
contenitori di proprietà dei pod che sono stati cancellati vengono rimossi una volta che sono più vecchi di "MinAge".
I contenitori che non sono gestiti da Kubelet non sono soggetti alla garbage collection del contenitore.
User Configuration
Gli utenti possono regolare le seguenti soglie per ottimizzare la garbage collection delle immagini con i seguenti flag kubelet:
image-gc-high-threshold, la percentuale di utilizzo del disco che attiva la garbage collection dell'immagine. Il valore predefinito è 85%.image-gc-low-threshold, la percentuale di utilizzo del disco su cui tenta la garbage collection dell'immagine liberare. Il valore predefinito è 80%.
Permettiamo anche agli utenti di personalizzare la politica di raccolta dei rifiuti attraverso i seguenti flag kubelet:
minimum-container-ttl-duration, l'età minima per un container finito prima che sia raccolta dei rifiuti L'impostazione predefinita è 0 minuti, il che significa che ogni contenitore finito verrà raccolto.maximum-dead-containers-per-container, numero massimo di vecchie istanze da conservare per contenitore Il valore predefinito è 1.maximum-dead-containers, numero massimo di vecchie istanze di container da conservare globalmente. Il valore predefinito è -1, il che significa che non esiste un limite globale.
I contenitori possono potenzialmente essere raccolti prima che la loro utilità sia scaduta. Questi contenitori
può contenere log e altri dati che possono essere utili per la risoluzione dei problemi. Un valore sufficientemente grande per
maximum-dead-containers-per-container è altamente raccomandato per consentire almeno un contenitore morto
mantenuto per contenitore previsto. Un valore più grande per "massimo-dead-containers" è anche raccomandato per a
motivo simile. Vedi questo problema per maggiori dettagli.
Deprecation
Alcune funzionalità di raccolta dei rifiuti di Kubelet in questo documento verranno sostituite da sfratti di Kubelet in futuro.
Compreso:
| Bandiera esistente | Nuova bandiera | Motivazione |
|---|---|---|
--image-gc-high-threshold |
--eviction-hard o --eviction-soft |
i segnali di sfratto esistenti possono innescare la garbage collection delle immagini |
--image-gc-low-threshold |
--eviction-minimum-reclaim |
i reclami di sfratto ottengono lo stesso comportamento |
--maximum-dead-containers |
deprecato una volta che i vecchi log sono memorizzati al di fuori del contesto del contenitore | |
--maximum-dead-containers-per-container |
deprecato una volta che i vecchi log sono memorizzati al di fuori del contesto del contenitore | |
--minimum-container-ttl-duration |
deprecato una volta che i vecchi log sono memorizzati al di fuori del contesto del contenitore | |
--low-diskspace-threshold-mb |
--eviction-hard o eviction-soft |
lo sfratto generalizza le soglie del disco ad altre risorse |
--outofdisk-transition-frequency |
--eviction-pressure-transition-period |
lo sfratto generalizza la transizione della pressione del disco verso altre risorse |
Voci correlate
Vedi Configurazione della gestione delle risorse esterne per maggiori dettagli.
8 - Proxy in Kubernetes
Questa pagina spiega i proxy utilizzati con Kubernetes.
Proxy
Esistono diversi proxy che puoi incontrare quando usi Kubernetes:
- Il kubectl proxy:
- viene eseguito sul computer di un utente o in un pod - collega un localhost address all'apiserver di Kubernetes - il client comunica con il proxy in HTTP - il proxy comunica con l'apiserver in HTTPS - individua l'apiserver - aggiunge gli header di autenticazione
- è un proxy presente nell'apiserver - collega un utente al di fuori del cluster agli IP del cluster che altrimenti potrebbero non essere raggiungibili - è uno dei processi dell'apiserver - il client comunica con il proxy in HTTPS (o HTTP se l'apiserver è configurato in tal modo) - il proxy comunica con il target via HTTP o HTTPS come scelto dal proxy utilizzando le informazioni disponibili - può essere utilizzato per raggiungere un nodo, un pod o un servizio - esegue il bilanciamento del carico quando viene utilizzato per raggiungere un servizio
- Il kube proxy:
- è eseguito su ciascun nodo - fa da proxy per comunicazioni UDP, TCP e SCTP - non gestisce il protocollo HTTP - esegue il bilanciamento del carico - è usato solo per raggiungere i servizi
- Un proxy/bilanciatore di carico di fronte agli apiserver:
- la sua esistenza e implementazione variano da cluster a cluster (ad esempio nginx) - si trova tra i client e uno o più apiserver - funge da bilanciatore di carico se ci sono più di un apiserver.
- Cloud Load Balancer su servizi esterni:
- sono forniti da alcuni fornitori di servizi cloud (ad es. AWS ELB, Google Cloud Load Balancer)
- vengono creati automaticamente quando il servizio Kubernetes ha tipo LoadBalancer
- solitamente supporta solo UDP / TCP
- il supporto SCTP dipende dall'implementazione del bilanciatore di carico del provider cloud
- l'implementazione varia a seconda del provider cloud.
Gli utenti di Kubernetes in genere non devono preoccuparsi alcun proxy, se non i primi due tipi. L'amministratore del cluster in genere assicurerà che gli altri tipi di proxy siano impostati correttamente.
Richiedere reindirizzamenti
I proxy hanno sostituito le funzioni di reindirizzamento. I reindirizzamenti sono stati deprecati.
9 - Metriche del responsabile del controller
Le metriche del controller controller forniscono informazioni importanti sulle prestazioni e la salute di il responsabile del controller.
Cosa sono le metriche del controller
Le metriche del controller forniscono informazioni importanti sulle prestazioni del controller. Queste metriche includono le comuni metriche di runtime del linguaggio Go, come il conteggio go_routine e le metriche specifiche del controller come latenze delle richieste etcd o latenze API Cloudprovider (AWS, GCE, OpenStack) che possono essere utilizzate per valutare la salute di un cluster.
A partire da Kubernetes 1.7, le metriche dettagliate di Cloudprovider sono disponibili per le operazioni di archiviazione per GCE, AWS, Vsphere e OpenStack. Queste metriche possono essere utilizzate per monitorare lo stato delle operazioni di volume persistenti.
Ad esempio, per GCE queste metriche sono chiamate:
cloudprovider_gce_api_request_duration_seconds { request = "instance_list"}
cloudprovider_gce_api_request_duration_seconds { request = "disk_insert"}
cloudprovider_gce_api_request_duration_seconds { request = "disk_delete"}
cloudprovider_gce_api_request_duration_seconds { request = "attach_disk"}
cloudprovider_gce_api_request_duration_seconds { request = "detach_disk"}
cloudprovider_gce_api_request_duration_seconds { request = "list_disk"}
Configurazione
In un cluster, le metriche di controller-manager sono disponibili da http://localhost:10252/metrics
dall'host su cui è in esecuzione il controller-manager.
Le metriche sono emesse in formato prometheus.
In un ambiente di produzione è possibile configurare prometheus o altri strumenti di misurazione delle metriche per raccogliere periodicamente queste metriche e renderle disponibili in una sorta di database di serie temporali.
10 - Installazione dei componenti aggiuntivi
I componenti aggiuntivi estendono la funzionalità di Kubernetes.
Questa pagina elenca alcuni componenti aggiuntivi disponibili e collegamenti alle rispettive istruzioni di installazione.
I componenti aggiuntivi in ogni sezione sono ordinati alfabeticamente - l'ordine non implica uno stato preferenziale.
Networking and Network Policy
- ACI fornisce funzionalità integrate di networking e sicurezza di rete con Cisco ACI.
- Calico è un provider di sicurezza e rete L3 sicuro.
- Canal unisce Flannel e Calico, fornendo i criteri di rete e di rete.
- Cilium è un plug-in di criteri di rete e di rete L3 in grado di applicare in modo trasparente le politiche HTTP / API / L7. Sono supportate entrambe le modalità di routing e overlay / incapsulamento.
- CNI-Genie consente a Kubernetes di connettersi senza problemi a una scelta di plugin CNI, come Calico, Canal, Flannel, Romana o Weave.
- Contiv offre networking configurabile (L3 nativo con BGP, overlay con vxlan, L2 classico e Cisco-SDN / ACI) per vari casi d'uso e un ricco framework di policy. Il progetto Contiv è completamente open source. Il programma di installazione fornisce sia opzioni di installazione basate su kubeadm che non su Kubeadm.
- Flannel è un provider di reti sovrapposte che può essere utilizzato con Kubernetes.
- Knitter è una soluzione di rete che supporta più reti in Kubernetes.
- Multus è un multi-plugin per il supporto di più reti in Kubernetes per supportare tutti i plugin CNI (es. Calico, Cilium, Contiv, Flannel), oltre a SRIOV, DPDK, OVS-DPDK e carichi di lavoro basati su VPP in Kubernetes.
- NSX-T Container Plug-in (NCP) fornisce l'integrazione tra VMware NSX-T e orchestratori di contenitori come Kubernetes, oltre all'integrazione tra NSX-T e piattaforme CaaS / PaaS basate su container come Pivotal Container Service (PKS) e OpenShift.
- Nuage è una piattaforma SDN che fornisce una rete basata su policy tra i pod di Kubernetes e non Kubernetes con visibilità e monitoraggio della sicurezza.
- Romana è una soluzione di rete Layer 3 per pod network che supporta anche API NetworkPolicy. Dettagli di installazione del componente aggiuntivo di Kubeadm disponibili qui.
- Weave Net fornisce i criteri di rete e di rete, continuerà a funzionare su entrambi i lati di una partizione di rete e non richiede un database esterno.
Service Discovery
- CoreDNS è un server DNS flessibile ed estensibile che può essere installato come in-cluster DNS per pod.
Visualization & Control
Dashboard è un'interfaccia web dashboard per Kubernetes.
Legacy Add-ons
qui ci sono molti altri componenti aggiuntivi documentati nella directory deprecata cluster / addons.
Quelli ben mantenuti dovrebbero essere collegati qui.